Medications
Last updated on 2026-04-28 | Edit this page
Estimated time: 0 minutes
Overview
Questions
Where are medications stored ?
How do you trace the relationship between concepts from different vocabularies?
Objectives
Know that exposure of a patient to medications is stored in the
drug_exposuretableUnderstand that drug concepts can be at different levels of granularity
Understand that source values are mapped to a standard vocabulary
Understand how to access the concentration or strength of an exposure using the
drug_strengthtable
Introduction
This episode considers medications (the drug exposure table) in the OMOP Common Data Model (CDM).
For this episode we will be using a sample OMOP CDM database that is pre-loaded with data. This database is a simplified version of a real-world OMOP CDM database and is intended for educational purposes only.
(UCLH only) This will come in a similar form as you would get data if you asked for a data extract via the SAFEHR platform (i.e. a set of parquet files).
As part of the setup prior to this course you were asked to download
and install the sample dataset. If you have not done this yet, please
refer to the setup instructions. For now, we
will assume that you have the sample OMOP CDM dataset available on your
local machine at the following path: ./data/omop/ and the
functions in a folder ./code/parquet_dataset.
You will then need to load the database as shown in the previous episode.
R
library(dplyr)
open_omop_dataset <- function(path) {
# iterate over table level directories
list.dirs(path, recursive = FALSE) |>
# exclude folder name from path and use it as index for named list
purrr::set_names(~ basename(.)) |>
# "lazy-load" list of parquet files from specified folder
purrr::map(arrow::open_dataset)
}
R
omop <- open_omop_dataset("./data/omop")
and the useful functions we created in the previous episode to look up concept names and ids.
R
get_concept_name <- function(omop_obj, id) {
omop_obj$concept |>
filter(concept_id == id) |>
select(concept_name) |>
collect()
}
R
get_concept_id <- function(omop_obj, name) {
omop_obj$concept |>
filter(concept_name == name) |>
select(concept_id) |>
collect()
}
Drug exposure
The OMOP drug_exposure
table stores exposure of a patient to medications. The purpose of
records in this table is to indicate an exposure to a certain drug as
best as possible. In this context a drug is defined as an active
ingredient. Drug Exposures are defined by Concepts from the Drug domain,
which form a complex hierarchy. As a result, one
drug_source_concept_id may map to multiple standard
concept_ids if it is a combination product. Records in this
table represent prescriptions written, prescriptions dispensed, and
drugs administered by a provider to name a few. The
drug_type_concept_id can be used to find and filter on
these types. This table includes additional information about the drug
products, the quantity given, and route of administration.
The drug_exposure table contains the following columns
(among others not listed here):
| Column Names | Description of content |
|---|---|
| drug_exposure_id | Unique identifier for each drug exposure |
| person_id | Identifier for the patient |
| drug_concept_id | Standard concept identifier for the drug |
| drug_exposure_start_date | Date the drug exposure started |
| drug_exposure_start_datetime | Date and time the drug exposure started |
| drug_exposure_end_date | Date the drug exposure ended |
| drug_exposure_end_datetime | Date and time the drug exposure ended |
| drug_type_concept_id | Concept identifier for the type of drug exposure |
| quantity | The quantity of the drug administered |
| route_concept_id | Concept identifier for the route of administration |
| visit_occurrence_id | Identifier for the visit during which the drug was administered |
| drug_source_concept_id | OMOP concept ID for the source value |
Drug data can be very complicated, as can the process of converting from the source data to OMOP. You may not find what you expect depending on this and the quality of the source data.
Drug concepts
The standard OHDSI drug vocabularies are called RxNorm
and RxNormExtension. RxNorm contains all drugs
currently on the US market. RxNormExtension is maintained
by the OHDSI community and contains all other drugs.
A particular concept_id can be at one of a number of
different levels in a drug hierarchy.
Challenge
List the main levels of drug concepts in RxNorm from the
concept table (e.g. the concept_class_id).
R
omop$concept |>
filter(vocabulary_id == "RxNorm") |>
select(concept_class_id) |>
distinct() |>
arrange(concept_class_id) |>
collect()
OUTPUT
# A tibble: 4 × 1
concept_class_id
<chr>
1 Clinical Drug
2 Clinical Drug Form
3 Ingredient
4 Quant Branded DrugAnswer: There are more levels than shown here, but that is a disadvantage of using a small sample database. In a full OMOP CDM database you would see more levels.
CODING NOTE: The distinct() function is
used to get unique values of concept_class_id for the
RxNorm vocabulary. The arrange() function is then used to
sort these values in alphabetical order for easier reading.
A fuller example of the drug concept hierarchy in RxNorm is shown in the table below.
| RxNorm concept_class_id | Description |
|---|---|
| Clinical Drug | A combination of an ingredient, strength, and dose form (e.g., Ibuprofen 200 mg Oral Tablet). |
| Clinical Drug Comp | A drug component with strength but no form (e.g., Ibuprofen 200 mg). |
| Clinical Drug Form | A drug with a specific dose form but no strength (e.g., Ibuprofen Oral Tablet). |
| Quant Clinical Drug | A clinical drug with a specific quantity (e.g., Ibuprofen 200 mg Oral Tablet 1). |
| Ingredient | A base active drug ingredient, without strength or dose form (e.g., Ibuprofen). |
There are also concepts for Branded drugs and for packs of drugs (e.g. a box of 30 tablets) but these are not shown in this sample table.
Drug mapping in the NHS
Drugs in the NHS are standardised to the NHS Dictionary of Medicines
and Devices (dm+d). dm+d is included in OMOP so there are values of OMOP
concept_id for each dm+d. However because dm+d is not a standard
vocabulary in OMOP it is translated once more to get to a standard OMOP
concept_id in RxNorm or RxNormExtension
that can be used in collaborative studies. If there is a
drug_concept_id value of 0 and there are source codes, this
can be because that drug doesn’t map to a standard concept. Reminder
that the source values are stored in these columns.
Challenge
Look up the concept_id 871182 and
search through the concept table by drug name to find the likely concept
in RxNorm and its concept_id.
R
# look up the concept entry
dmd_concept <- omop$concept |>
filter(concept_id == 871182) |>
select(concept_id, concept_name, domain_id, vocabulary_id, concept_class_id) |>
collect()
dmd_concept
OUTPUT
# A tibble: 1 × 5
concept_id concept_name domain_id vocabulary_id concept_class_id
<int> <chr> <chr> <chr> <chr>
1 871182 Lorazepam 1mg tablets Drug dm+d VMP R
# this is the dose of lorazepam
# now look up any concepts that have a similar name
similar <- filter(omop$concept, grepl('Lorazepam', concept_name, TRUE)) |>
collect()
similar
OUTPUT
# A tibble: 4 × 10
concept_id concept_name domain_id vocabulary_id standard_concept
<int> <chr> <chr> <chr> <chr>
1 871182 Lorazepam 1mg tablets Drug dm+d ""
2 19019113 lorazepam MG Oral Tablet Drug RxNorm "S"
3 35777064 1 ML Lorazepam 4 MG/ML In… Drug RxNorm Exten… "S"
4 36816707 Lorazepam 4mg/1ml solutio… Drug dm+d ""
# ℹ 5 more variables: concept_class_id <chr>, concept_code <chr>,
# valid_start_date <date>, valid_end_date <date>, invalid_reason <chr>Answer: We can see from the resulting table
that there are entries for each lorazepam dose from both the dm+d and
RxNorm vocabularies. The concept_id 871182
corresponds to the dm+d concept “Lorazepam 1mg tablets”. This seems maps
to the RxNorm concept “lorazepam Oral Tablet” which has
concept_id 19019113, but without knowing
the quantity we can’t be sure which dose it maps to. This is an example
of the complexity of drug data and the mapping process.
CODING_NOTE: The function grepl() is
used to find all concepts that have “Lorazepam” in their name. We have
added the ignore.case = TRUE argument to make the search
case-insensitive. This allows us to find all relevant concepts
regardless of how they are capitalized in the concept names.
This is a snapshot of the Athena table for code 871182. Athena is the OHDSI tool for exploring the OMOP vocabularies and concept relationships. It is available online at https://athena.ohdsi.org/. You can use it to look up concepts and their relationships to other concepts in the OMOP CDM.
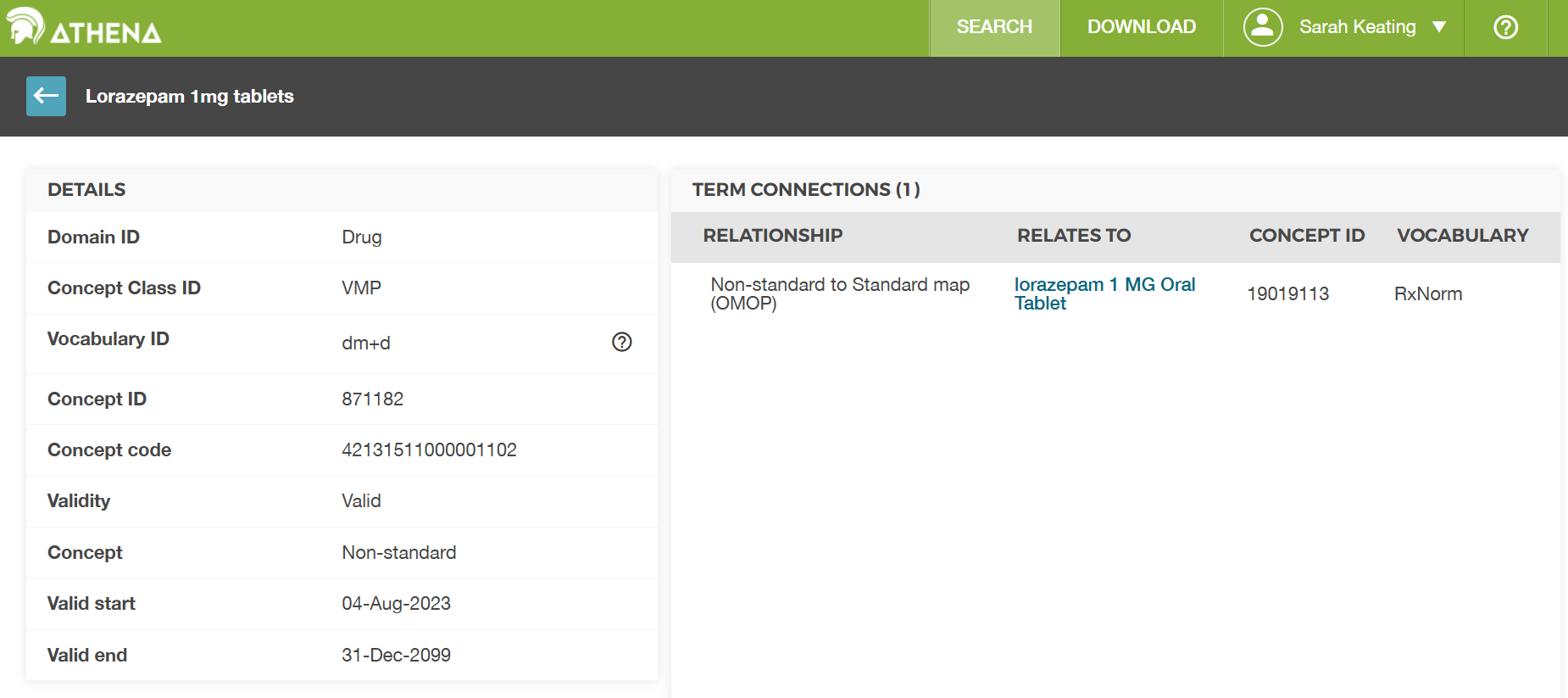
Looking at the entry for concept_id
871182 we can see that it is in the dm+d vocabulary. We
can see that is connected to the RxNorm concept “lorazepam 1 MG Oral
Tablet” which has concept_id 19019113. So
our assumption above was correct, but the concept table in our dataset
didn’t fill in the name fully so we couldn’t be sure without looking it
up in the official table. Within the OMOP CDM there are tables
(concept_relationship) where you can look up the
relationships between concepts programatically, so this doesn’t have to
be manually done by using Athena.
Quantity
There are other vocabulary tables for the OMOP CDM other than the
concept table. drug_strength
stores the amount of concentration and associated units of a specific
ingredient within a drug product.
The drug_strength table contains the following columns
(among others not listed here):
| Column Names | Description of content |
|---|---|
| drug_concept_id | Concept representing the Branded Drug or Clinical Drug Product |
| ingredient_concept_id | Concept representing the active ingredient contained within the drug product |
| amount_value | Amount of active ingredient |
| amount_unit_concept_id | Concept for the unit of measure for the
amount_value
|
| numerator_value | Concentration of the active ingredient in the drug product |
| numerator_unit_concept_id | Concept for the unit of measure for
numerator_value
|
| denominator_value | Amount of total liquid in the drug product |
| denominator_unit_concept_id | Concept for the unit of measure for
denominator_value
|
Drug data can be very complicated, as can the process of converting from the source data to OMOP. You may not find what you expect depending on this and the quality of the source data.
Challenge
Work out what drugs person_id 2 was exposed to and
the quantity of each drug by joining to the drug_strength
table. Please display the names for the drug_concept_id.
Once you have this, also display the names of
amount_unit_concept_id,
numerator_unit_concept_id and
denominator_unit_concept_id.
R
# filter for person_id 2
person_2_drugs <- omop$drug_exposure |>
filter(person_id == 2) |>
select(drug_exposure_id, drug_concept_id, drug_source_concept_id, quantity)
# now create a table with humanly readable names for the drug_concept_id and drug_source_concept_id.
# first, get the concept names for drug_concept_id
concept_names <- omop$concept |>
select(concept_id, concept_name)
# join with person_2_drugs
person_2_drugs <- person_2_drugs |>
left_join(concept_names, by = join_by(drug_concept_id == concept_id)) |>
rename(drug_concept_name = concept_name)
# Join in the drug strength table and get the names
person_2_drugs_with_strength <- person_2_drugs |>
left_join(omop$drug_strength, by = join_by(drug_concept_id)) |>
# join in names of concepts
left_join(concept_names, by = join_by(amount_unit_concept_id == concept_id)) |>
rename(amount_unit_concept_name = concept_name) |>
left_join(concept_names, by = join_by(numerator_unit_concept_id == concept_id)) |>
rename(numerator_unit_concept_name = concept_name) |>
left_join(concept_names, by = join_by(denominator_unit_concept_id == concept_id)) |>
rename(denominator_unit_concept_name = concept_name) |>
select(
drug_exposure_id,
drug_concept_name,
quantity,
amount_value,
amount_unit_concept_name,
numerator_value,
numerator_unit_concept_name,
denominator_value,
denominator_unit_concept_name
) |>
collect()
person_2_drugs_with_strength
OUTPUT
# A tibble: 7 × 9
drug_exposure_id drug_concept_name quantity amount_value
<int> <chr> <dbl> <dbl>
1 38914 1 ML Lorazepam 4 MG/ML Injectable Solu… 0.25 NA
2 43725 100 ML Glucose 50 MG/ML Injectable Sol… 0 NA
3 44660 2 ML Ondansetron 2 MG/ML Injectable so… 1 NA
4 29587 lorazepam MG Oral Tablet 1 1
5 34505 promethazine hydrochloride 25 MG Oral … 1 25
6 34506 lorazepam MG Oral Tablet 1 1
7 47679 promethazine hydrochloride 25 MG Oral … 1 25
# ℹ 5 more variables: amount_unit_concept_name <chr>, numerator_value <dbl>,
# numerator_unit_concept_name <chr>, denominator_value <dbl>,
# denominator_unit_concept_name <chr>Answer: Person_id 2 was exposed to three drugs. - They had three doses of lorazepam: two separate doses of 1 x 1mg lorazepam tablets and one dose of 0.25 x 4mg/ml injectable lorazepam. - They had two doses of 1 x 25mg promethazine hydrochloride tablets. - They had one dose of 1 x 2mg/ml injectable ondansetron.
(Note the quantity of glucose is zero.)
CODING NOTE: We first filter the
drug_exposure table for person_id
2 and select the relevant columns. Then we join this
with the concept table to get the human readable name for
the drug. We then join the drug_strength and join the
concept table for each of the concept column in the
drug_strength table.
Administration route
Challenge
Find the route of administration for the drugs person_id 2 was exposed to.
R
# we could have used the same table we created in the previous challenge
person_2_drugs <- omop$drug_exposure |>
filter(person_id == 2) |>
select(drug_concept_id, drug_source_concept_id, quantity, route_concept_id) |>
left_join(concept_names, by = join_by(drug_concept_id == concept_id)) |>
rename(drug_concept_name = concept_name)
# join with person_2_drugs
person_2_drugs <- person_2_drugs |>
left_join(concept_names, by = join_by(route_concept_id == concept_id)) |>
rename(route_concept_name = concept_name) |>
collect()
person_2_drugs
OUTPUT
# A tibble: 7 × 6
drug_concept_id drug_source_concept_id quantity route_concept_id
<int> <int> <dbl> <int>
1 19019113 871182 1 4132161
2 40180065 874635 1 4132161
3 19019113 871182 1 4132161
4 35777064 36816707 0.25 4302612
5 21049614 21255277 0 4171047
6 35778239 36817124 1 4171047
7 40180065 874635 1 4132161
# ℹ 2 more variables: drug_concept_name <chr>, route_concept_name <chr>CODING NOTE: We follow a similar process as in the
previous challenge, but this time we also select the
route_concept_id and join it with the concepts
table to get the human-readable name for the route of administration.
The resulting table now includes the route of administration for each
drug exposure.
- Know that exposure of a patient to medications is mainly stored in the drug_exposure table
- Understand that drug concepts can be at different levels of granularity
- Understand that source values are mapped to a standard vocabulary
- Understand how to access the concentration or strength of an
exposure using the
drug_strengthtable